Most likely paths to error when estimating the mean of a reflected random walk
Ken Duffy and Sean Meyn
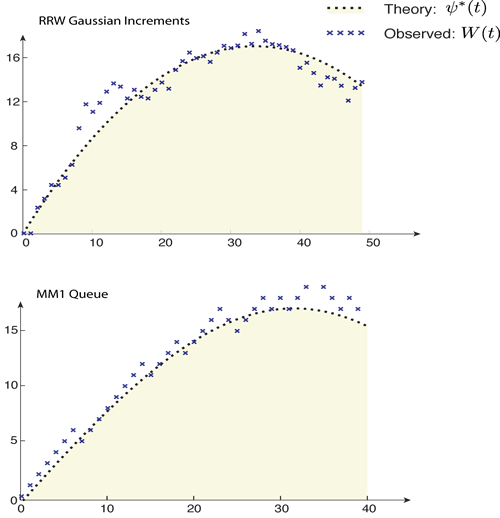
Abstract: Simulation of the mean position of a skip-free Markov chain can be hard, even when the chain is geometrically ergodic. The Large Deviation Principle (LDP) holds for deviations below the mean, but for deviations at the usual speed above the mean the rate function is null. For example, even the stable MM1 queue does not satisfy the LDP. Moreover, this simple model and other reflected random walks exhibit exotic yet quantifiable sample path behavior conditioned on a large sample mean. Two techniques can be used to combat these dynamics to improve simulation algorithms: Multiple control variates, or screening.
Keywords: Reflected random walks, mean position simulation, large deviations, most likely paths.
|
|||
References @article{dufmey10, @unpublished{blaglymey12, @article{mey06a,
|
|||